如果你在一家对数据安全性很高的公司工作,团队规定不允许提交数据到第三方服务上,甚至连服务器内存、CPU使用情况等监控数据都不行,那对于像Alinode这样监控和排查问题的大杀器基本都是无福享用了。大多数情况不得不面临自己开发一套类似监控体制去为生产环境保驾护航。
数据
Node.js是单进程的,即使像Egg.js这样的项目存在Agent、多个Worker进程,但依旧应该把它们分为独立的进程对待,所以监控的粒度是进程级别。
基础数据
- 进程级别:内存、CPU、EventLoop、GC、调用该系统的时间消耗、该系统调用它人系统的时间消耗等。
- 系统级别:负载均衡 (
os.loadavg())
上述这些数据,有些Node.js API直接暴露出来,有些需要写C++扩展去调用底层的V8 API来获取,好在市面上存在比较多的此类类库,比如IBM appmetrics就不错,它还有很多额外的监控数据可以收集,主动定时将它们提交到Elasticsearch,在用Grafana加载出来,还是很容易做到的。
内存堆栈快照
- 通过多份内存堆栈快照可以帮助我们定位内存溢出的原因。
CPU火焰图
- 通过它可以让我们知道是代码的哪部分导致CPU非常繁忙。
上面这2个文件在系统调优和排查问题时起到至关重要的帮助,但是它们都是以文件的形式存储,又不像基础数据那么简易可以直接塞进DB里;另外获取这些资源过程是影响应用性能的,比如内存堆栈快照因为要罗列出所有的堆栈对象相互之间的关系和字节大小需要一定的计算量和时间,在此过程中系统处于无法响应的状态。为此,我们需要设计一套方法,在需要的时候去通知对应的Node.js进程,被动生成这些文件,而不是向先前那样主动收集。
命令&传输
我们需要通过一些方法,告诉对应的Node.js进程该干些什么事情,是生成内存堆栈快照还是CPU火焰图,又或是别的什么。需要一个发送命令的地方,也需要一种方式将命令发送给指定的Node.js进程。将一个个孤立的Node.js进程连接起来有很多方式,比如TCP,或者HTTP。
我个人比较倾向用TCP,长链、双向、数据帧也轻巧很多,等等。像下图那样将他们连起来,仅用来示意,具体细节会有些不同,简单的粗暴将单箭头表示HTTP,双箭头表示TCP双向。
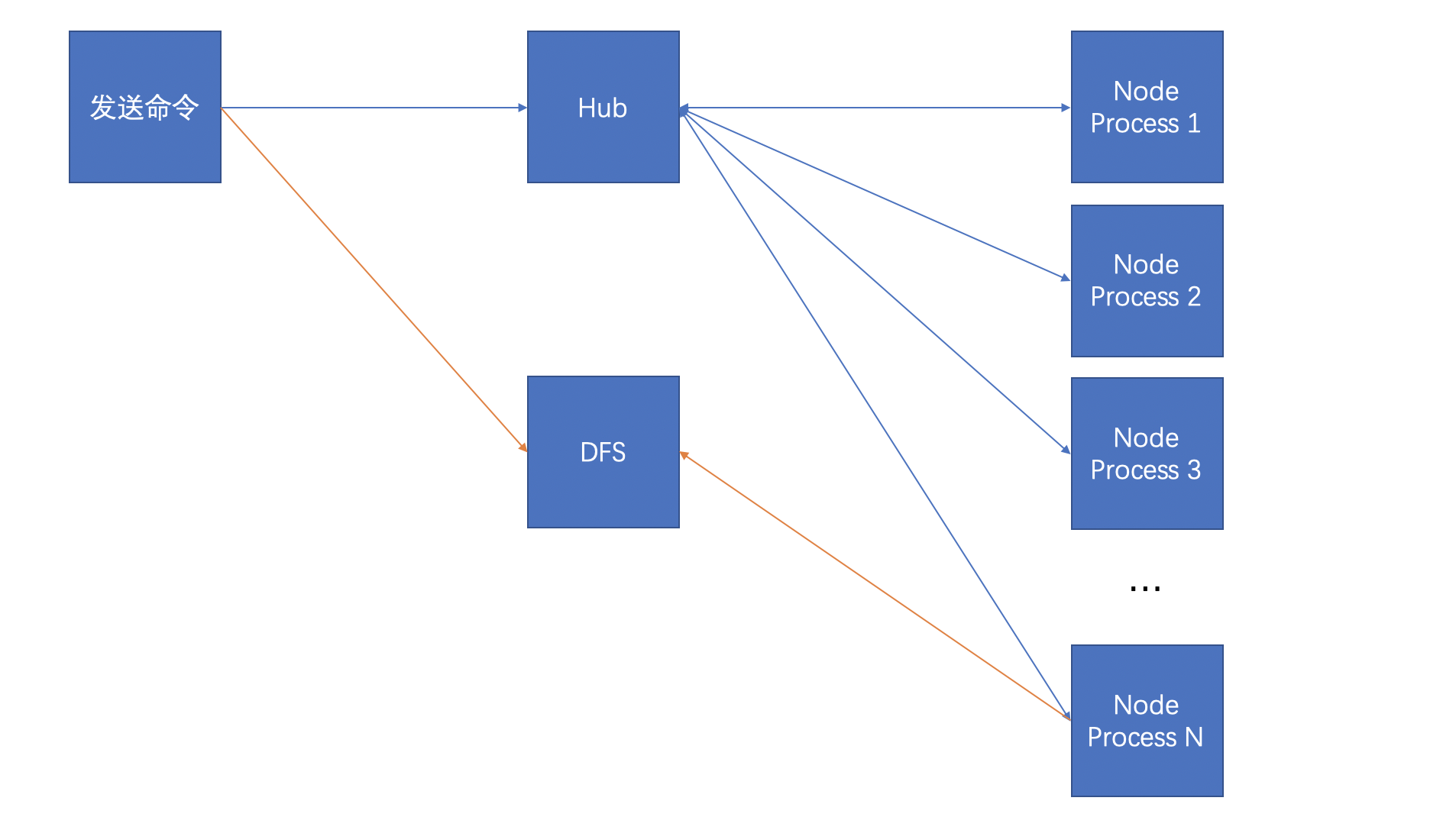
- 命令发送:一般会有一个Web界面,通过按钮提交命令请求。
- Hub:一个TCP服务,接受命令并将其转发到对应的Node.js进程上。
- Node.js Process: 可能一台服务器(或者Docker等)就一个Node.js进程,如Express;也有可能如Egg.js一样是多个Node.js进程。
- DFS:因为现在的服务基本都是部署在像Docker这样虚拟机上的,服务出现问题或人工原因很容易随时被系统销毁导致生产的快照或火焰图丢失,所以需要有个文件服务器持久化它们,因此一旦文件生产后就推送到文件服务器上待使用者去下载它们。
内存堆栈快照
Node.js Process监听到发来的命令,通过调用heapdump很容易获得内存堆栈快照,再将文件推送到DFS上。如果想像Alinode那样自动又直接显示内存信息的话,改下devtools-frontend,将其加入到系统中即可。
CPU火焰图
火焰图比其它的数据麻烦很多,官方有专门的文档说明了整个流程,总的来说需要perf和FlameGraph这两个工具,具体的方法随意Google都能查到很多,就不多叙述了,关键是如何将它融入到上述的框架中呢?
假设和之前一样,Node.js进程用socket.on("readable",callback) 或 socket.on("data",callback)接受命令,并在callback中开启一个新的进程来执行perf等shell脚本,那么生成的火焰图不准确,为何?
Node.js是单进程,JavaScript部分是事件循环,密集计算会阻塞其它的操作,比如运行一个斐波那契数列计算。此刻,其它的异步任务就算完成也无法得到执行,比如底层IO获得了命令,但是由于JavaScript堵塞了而无法执行callback创建新进程执行shell脚本。等到斐波那契数列执行完后,callback才被执行。而我们火焰图需要排查的就是什么导致CPU一直繁忙的嗡嗡作响,而上述的问题就是密集的斐波那契数列计算,但是由于JavaScript的执行机制而有可能错过了开启perf的时机。大多数的时候,我们都是发现进程阻塞了或者CPU一直处于繁忙而去主动命令进程开启perf排查问题,所以这个方法获得的数据并不准确。
如果当前进程一直进程因为繁忙而无法执行新的JavaScript命令,那么我们是否可以通过一个简单的辅助进程来帮忙开启shell脚本呢?
实验
因为perf需要Linux环境,我们可以通过Docker在本地启动一个Node.js容器实验下,以Node.js 12为例。
下载完对应版本的Node.js Docker后,通过下面命令开启一个新的容器,必须带--privileged不然无法使用perf。
1 | docker run --privileged -itd node:12-buster /bin/bash // 启动 |
进入Docker容器后安装perf
1 | apt-get update |
1 | // index.js |
1 | // package.json |
- index.js: 创建一个辅助进程;执行斐波那契数列计算
- hepler.js: 将压缩的FlameGraph.zip解压 => 给相关文件执行权限 => 获得当前系统中除自己以外的Node.js进程号(因为可能是多个,所以是个数组,例子中假设就一个进程)=> 定时模拟获得生成火焰图的命令 => 执行 perf record => 延迟5秒后生成火焰图
- package.json: 启动 index.js 需要加上
--perf-basic-prof命令行参数;另外还需要unzipper类包
将他们通过docker cp 从本地上传到docker中,并执行npm i安装依赖。
1 | npm run dev // 开始实验 |
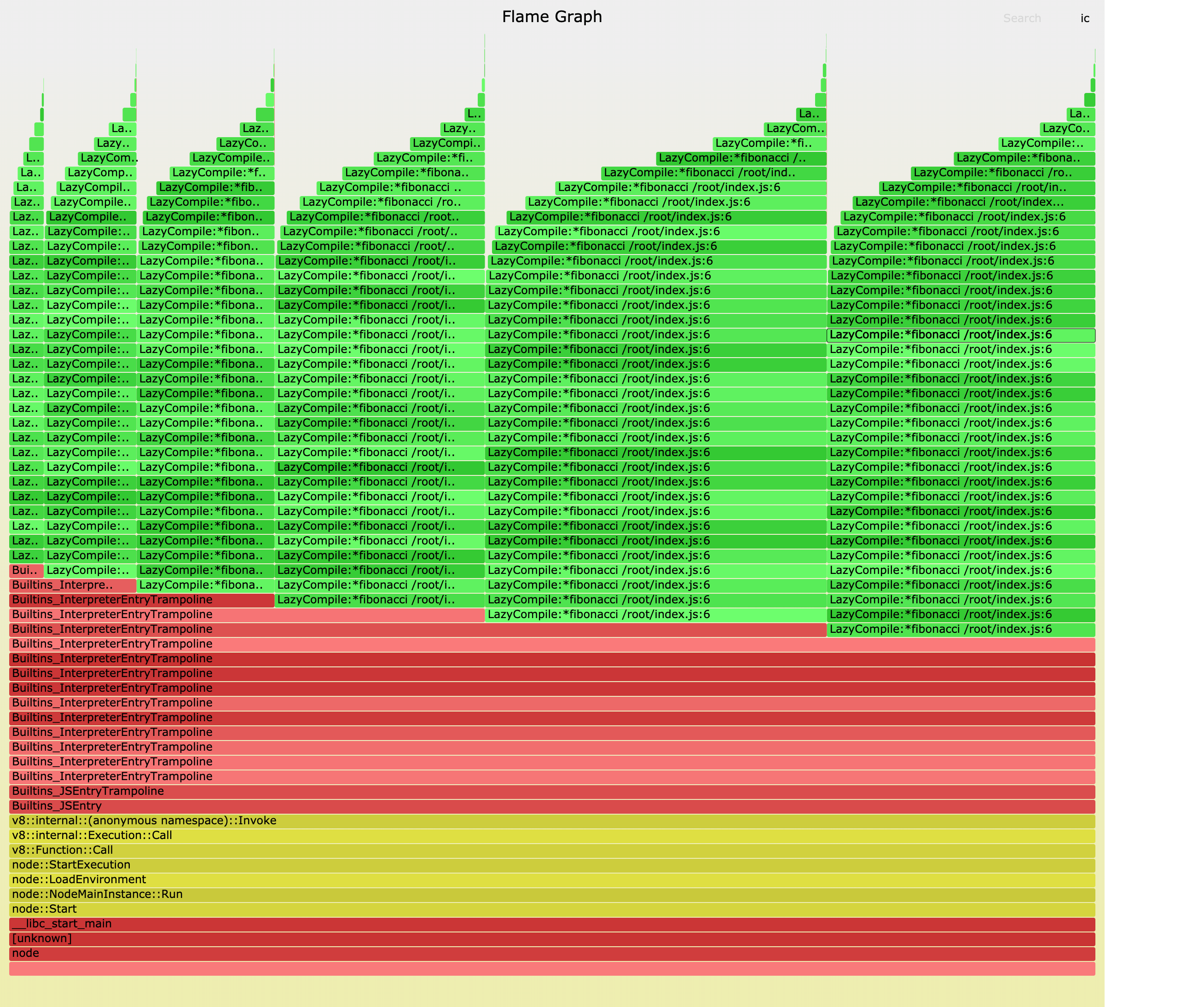
随着一阵的风扇狂响(CPU密集计算)之后,火焰图也生成好了,大致如下:
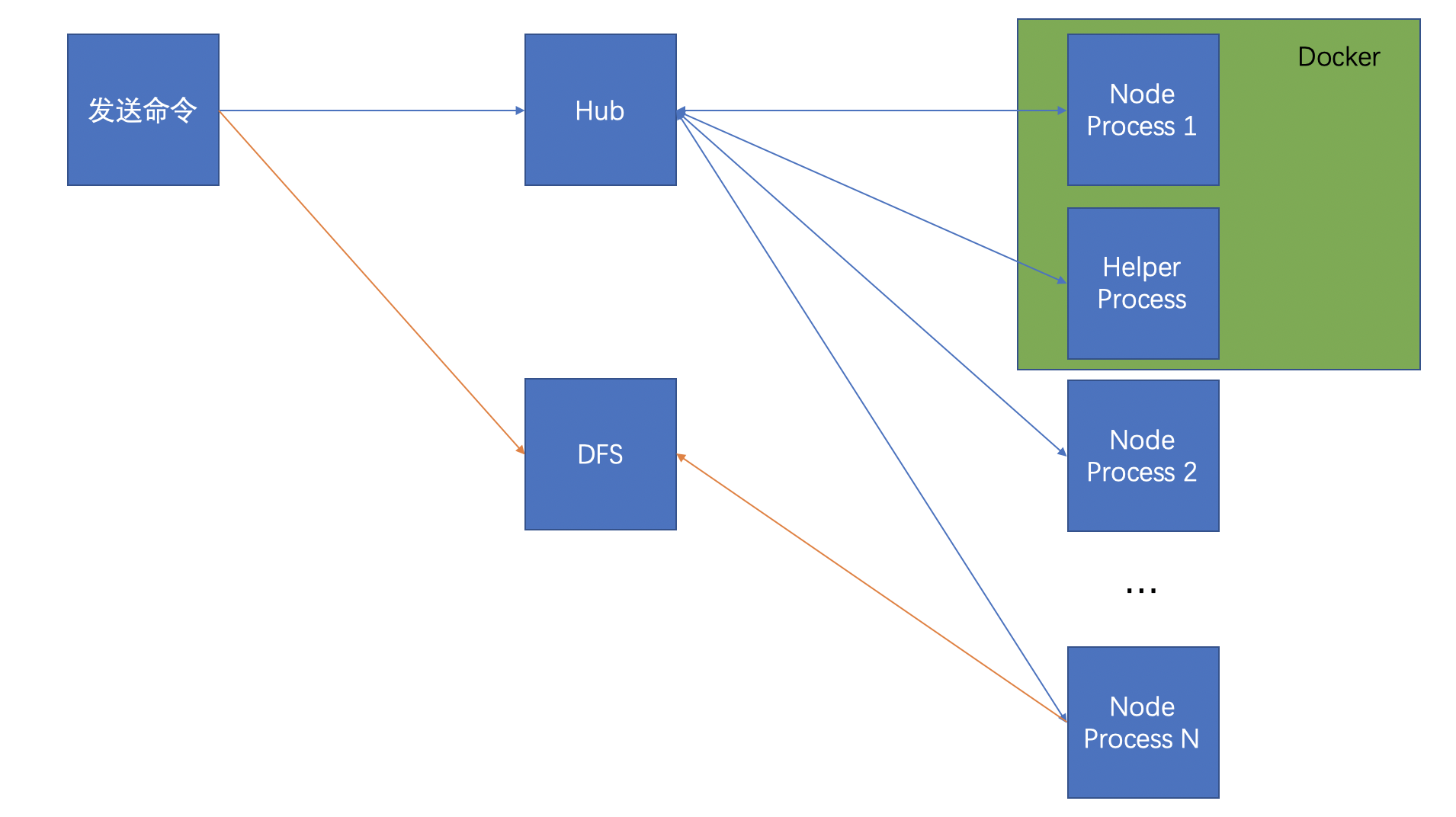
之前的框架也做部分调整,每个容器需要一个Helper.js进程
总结
我觉得程序员和程序猿之间的差别就在有没有一套好的监控体系和善用监控调优及排查问题的方法。如果没办法使用现成的第三方服务,往往需要自己动手去搭建,无论业务多么繁忙,唯有趁手的“兵器”才能取得真经,这是需要据理力争的东西。只有水下的冰够厚,水上的冰山才能更高。
Comments