之前写了一篇收集 Node.js 应用的内存堆栈快照和 CPU 火焰图文章,其中的架构非常粗糙,但是初步算是满足了现在的监控需求。不过随着业务的增长,单台TCP Server可定无法满足高可用的需求,一旦出现问题那就没办法持续使用了,所以需要一个重新设计和改造。
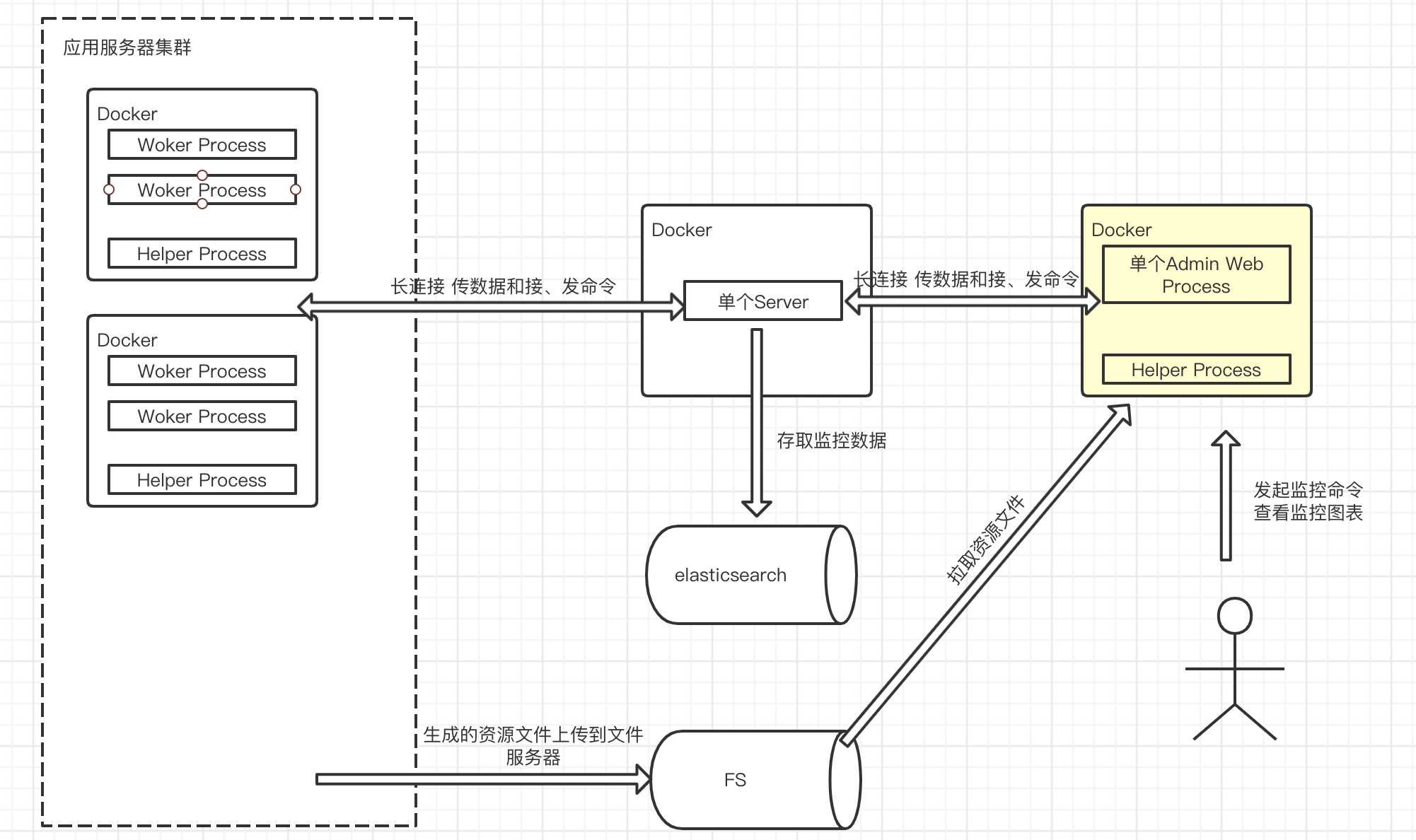
大致流程介绍:
一个 Docker 中,可能运行多个 Node.js 进程,比如 Egg.js 框架,另外Helper Process是用来做火焰图采集的,前面的文章提到过,目前它的功能相对单一应该被优化。
所有的 Node.js 进程都会被看做事一个Client通过 TCP 长连接连入Server,他们做双向通信,Client 将心跳和监控数据(CPU、内存、EventLoop、GC 等)源源不断送入 Server 中,Server 将对用的数据存入到 ES 中。
用户通过Admin Web可以查看每个应用的基础数据图表,发送生成内存堆栈信息和 CPU 火焰图的信息给指定的 Client,Client 生成文件后上传到FS(文件系统),之后 Admin Web 去 FS 上抓取该文件。
Q:为什么是这样一个粗糙的设计?
- 以快速上线去生产验证可用性为目标之一,尽量减少对其它系统的依赖,依赖
ES是为了存数据、FS是为了存文件,过多的依赖对于部署上线还是测试链路都是增加成本,在人力有限的情况下拖的越久越容易杀死项目。
Q:为什么用长链接而不是短链接?
- 长链接的好处在简单模型下有个最大的好处就是我不需要去维护客户端是否存活,因为一旦客户端挂了,那么它就会自动断开,既能发送监控警报,又不需要做相关的治理工作,治理工作又是一个细活。
- 另外客户端没有将数据集中定时批量发送,而是每次取到相关数据就发送给 Server。为了减少开销就用了长链接,自定义的协议传输效率也高。
- 在开发过程中,长链接的开发模型比短连接复杂很多,不容易维护。
Q:目前遇到的问题和思考
- 单机 Server 一旦挂了就没办法继续监控,导致的风险极大,需要做集群,但是长链接并不适合做扩展,所以必须长改短。
- 如果 Server 是集群,那势必需要 Client 去找到它,那么将引入
服务注册和发现功能,比如 Eureka、Consul 等,将 Client、Server 和 Admin Web 连入。 - 有了 Eureka、Consul 之类中间件,其实 Admin Web 可以直接通过它找到 Client,不过为了功能单一性,还是让 Server 转发用户命令。
- 之前的 Helper Process 是在做火焰图时候临时加入,所有的
Worker Process都是平等的 Client,在启动它的时候存在竞争问题,哪里一个 Client 去启动它呢?可以做一个类似 Egg.js 的启动命令,有 Master 进程、数个 Worker 进程已经一个 Helper Process。当然在 Egg.js 框架里,完全可以用 Agent 进程代替它,写个相关插件即可。 - 如果所有的 Client 和 Helper Process 都在 Master 下,那么我们可以通过 Helper Process 代理将所有的 Client 基础数据批量上传到 Server,通过父进程 Master 做转发,这样也减轻了不断传数据的性能瓶颈;另外所有的 Client 注册到注册中心也不合适,也可以通过 Helper Process 代理,这样每个 Docker 就一个服务注册了。
- 生成文件的过程是漫长的,不可能让短链接一直等,所以需要一个消息列队去通知 Admin Web,XXXX Client 的 XXXX 文件已经好了,让它去 FS 上拉取,需要引入 RMQ 等。
- 为 Admin Web 可以方便获取 Client 列表,可以将注册中心里的服务信息格式处理后存在 Redis 中,这样就引入了 Redis,如果不平凡刷新这个列表可以每次读取注册中心里的数据做格式处理。
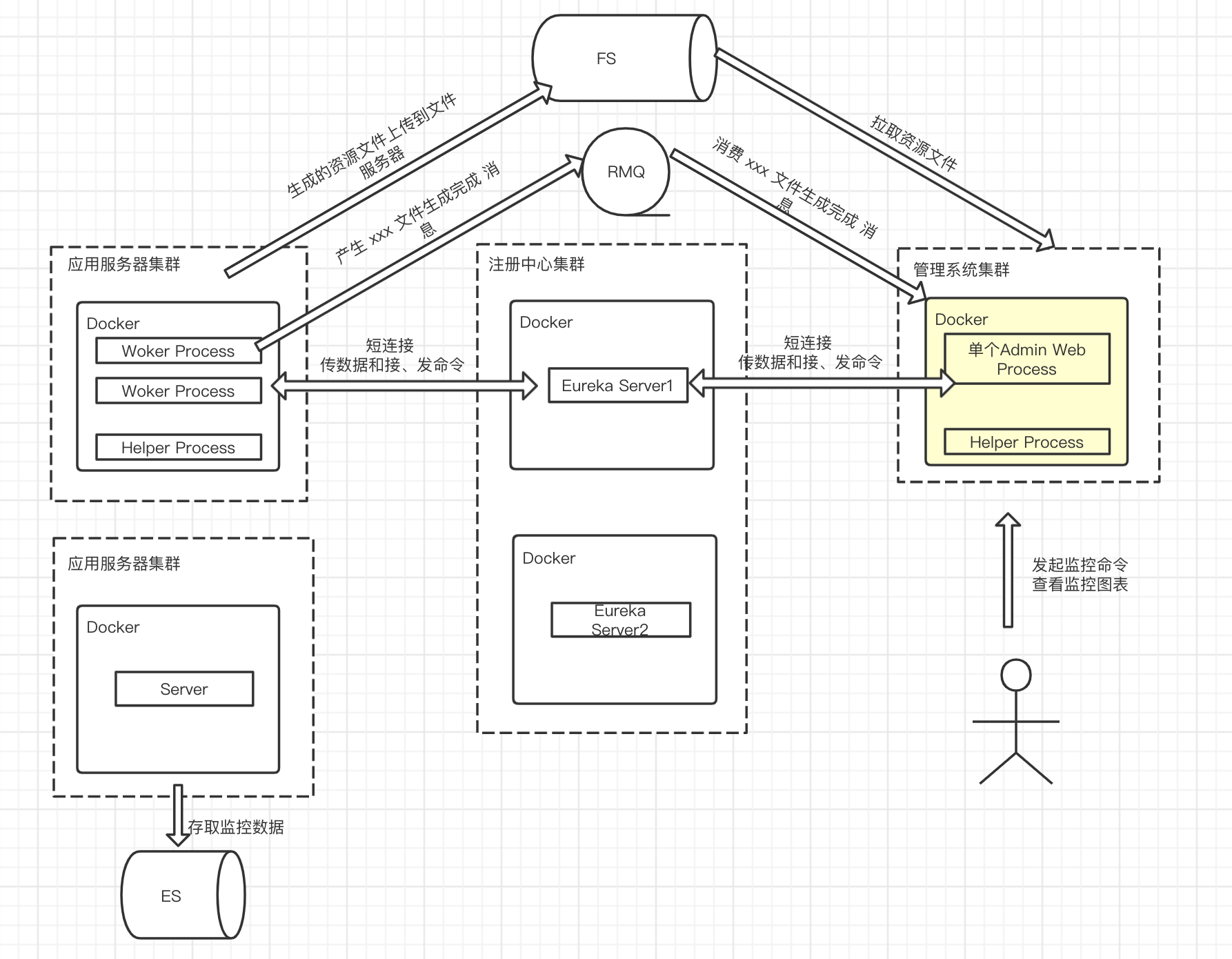
综上思考,Server 依旧做信息的存储和命令的转发工作,Admin Web 依旧是操作命令的入口,而整个 Client 端偏向 Egg.js 的风格。渐渐的整个监控中心就变得像一个微服务集群那样存在和运行,不同阶段有不同阶段的任务目标,讲不定之后会有新的挑战需要迭代。
Comments